Oforth Memory Management and garbage collector
I - Memory management
Here is a running Oforth system and where memory is allocated :
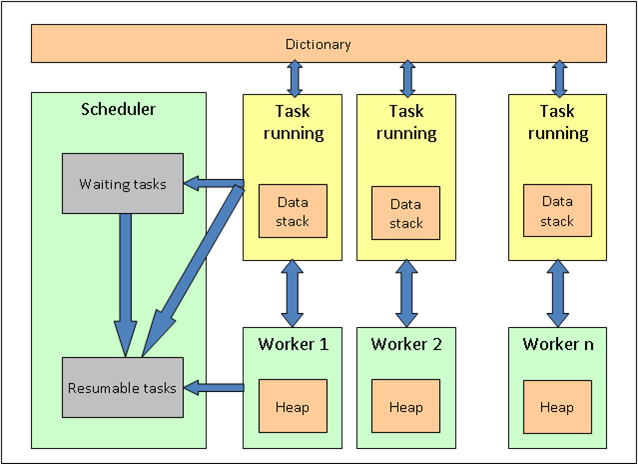
An Oforth system contains :
- Dictionary : it is a memory area when all words are stored. It also contains all static objects declared into words (constant strings, floats, ...). All tasks have access to the dictionary. It only contains immutable objects and is not concerned by the garbage collector phase.
- Workers : they are OS threads that run tasks. When a task is stopping (because the task is finished or enter into wait state, the worker retrieves a new task to run into the resumable tasks list. If this list is empty, it goes into sleep until a task is ready to run. A worker has its own dedicated heap and manages it.
- Tasks : they are small objects performed by workers. When a task is waiting for a resource (a channel, a socket, ...), it enters into WAIT state. A task has its own dedicated data stack. When a running task allocates an object, it asks to its worker to allocate it on the worker heap.
- Scheduler : It is a dedicated OS thread. The scheduler is the heart of an oforth system : it creates new workers (if needed), it detects events and send tasks waiting for those events to the resumable tasks list, it awakes sleeping workers when the resumable tasks list is not empty, and it raises GC events. The scheduler itself is not responsible to run GC. GC is performed by the workers.
At start up, there is one task (the interpreter) created and one worker. When the interpreter has finished to load the "lang" package, it will wait for input from the console. So the Oforth system is :
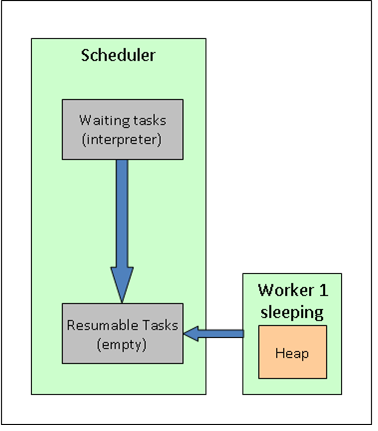
When a key is pressed, the scheduler detects it, send the interpreter task to the resumable tasks list and wake up the worker. The worker retrieves this task and resume it until the interpreter enter again into WAIT state.
II - Garbage collector
Each 120 milliseconds (or --WTn command line option parameter if set), the scheduler sends a GC event to workers. There are 2 kinds of garbages :
- Restrict garbage : the garbage collector will only checks for mutable objects. Living immutable objects are considered as used.
- Global garbage : the garbage collector will check all objects. It occurs after 9 restrict garbage collectors (so every 1200 milliseconds by default).
Since V0.9.22 release, Oforth runs an incremental mark and sweep garbage collector (GC) : the GC is no more a "stop the world" phase and tasks are allowed to run between GC steps until the GC is finished. Objective is to allow tasks to run at least every 100 microseconds during GC and to not restart GC steps before task have accomplished some amount of work.
From the garbage collector point of view :
- Used objects are on tasks stacks (data stack or return stack).
- Each worker is handling its own heap, and this heap must release objects that have been allocated by tasks and no more used.
So, the strategy is :
- All workers that are currently running a task stop it.
- During the mark phase, the workers retrieve all waiting tasks and mark used objects.
- During the sweep phase, each worker checks its heap and free all objects that are not marked.
- Workers are doing all this step by step in order to allow tasks to run between those steps.
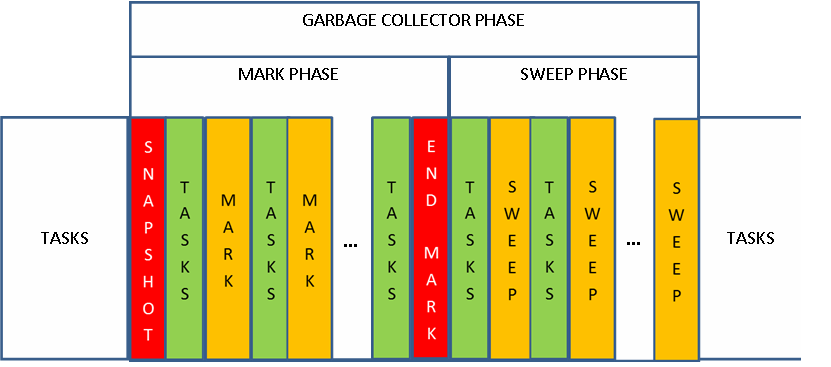
Here are the GC steps for one worker :
III - Mark phase
The mark phase is divided into steps :
The first step is a snapshot. It is a "stop the world" step. During this step, all tasks are scanned by workers and, for each task retrieved by a worker, all objects (but not objects attributes) that are present on the data stack and the return stack are stored into the worker Mark Stack. The mark stack is a stack dedicated to a worker that contains all the objects it must mark during the mark phase. This step can't be stopped and no task can run during this step.
Then, each worker begins to handle its mark stack until it is empty : an object is removed for the mark stack and is tagged as USED. All object attributes are pushed on the mark stack and the worker loops on its mark stack. When a number of objects has been handled and the Mark Stack is not empty, the worker stops its mark step and run resumable tasks. When tasks have used an amout of CPU, the worker go back to handle its mark stack again.
When all workers have processed their mark stack, they are synchronised to begin the sweep phase. This is also a "stop the world" step to be sure that all objects are marked before the sweep phase begin. After this point, workers are no more synchronised.
When a task is running during a mark phase, some adjustments must be done to not disturb GC : all objects created are created as USED by the worker and, if an object attribute is changed, the old value of the attribute is sent into current worker mark stack to be sure that it will be marked.
IV - Sweep phase
The sweep phase is also divided into steps where each worker handle its own heap.
It sets back to NOT USED objects marked as USED during the mark phase and free objects that were not tagged during the mark phase. When a number of objects has been handled and there is still heap to handle, the worker stops its sweep step and run resumable tasks. When tasks have used an amount of CPU, the worker go back to sweep its remaining heap.
When a task is running during a sweep phase, the only adjustement is on objects creation : they will continue to be created as USED until the memory pages used for allocation are sweeped. When sweeped, objects can now be created as NOT USED as if the GC was not running.
V - Current restrictions and possible optimizations
Dividing the GC phase into steps of duration of about 100 microseconds allows tasks to run between those steps : the GC is not more a "stop the world" phase. But, into current release, there are some situations where steps of 100 microseconds are not guaranted. Next releases will try to resolve those situations.
- Snapshot step can't be stopped to run tasks. There is no guarantee that it will last less than 100 microseconds.
- Lists must be entirely marked during a step and this can't be stopped.
- Mark stacks have a limited size : when the mark stack is full, next objects are directly marked until the mark stack is no more full.
- Operations on integers must finish before the task give CPU back to GC : with huge integers, this can lead to block the GC until the operation is done.
- Operations on sockets have to be revisited : even if sockets are non blocking, if a task is awaken because there is someting to do on a socket, currently, the operation itself can't be stopped.
There are also some optimizations to check, too :
- Perhap's the mark phase is too conservative when creating new objects : they are all marked as used.
- Workers that have finished their mark phase could help others that have more work to do. But this would need another synchronisation between workers.
VI - GC parameters
Some GC parameters can be defined on oforth command line. Those parameters are :
--XAn : "Amount" of CPU for tasks between GC steps.
This parameter allows to adjust how long tasks will run during GC steps. This value is a number of ticks. Ticks are taken on various points when a task is running. Default value is 300 and is adjusted to run tasks during 15 micro seconds between each GC step (on a Core i5). Increasing this value will allow tasks to run longer between GC step. As a drawback, GC will run longer and memory used will be greater.
--XGn : Amount of CPU for a GC step.
This parameter allows to adjust how long a gc step will run before giving back CPU to tasks. Default value is 6000 and is adjusted to run a GC step in about 100 micro seconds (on a Core i5). Decreasing this value will allow GC steps to take less time. As a drawback, GC will run longer (more steps will be needed to run the GC) and memory used will be greater.
--XTn : Number of milliseconds between 2 GC
This parameter defines number of milliseconds between 2 GC. Default value is 120 milliseconds. Increasing the value give more time to tasks, but will increase memory used.
--XMn : Memory (Kb) to reach before GC runs.
Default value is 1024 Kb. If memory allocated is less than this value, GC will never run. If memory allocated is greater than this value, GC will run (every 120 ms or --XTn parameter).
--XVn : Verbose level.
This parameter will output GC informations. Levels are 0, 1, 2 or 3. At level 0, no output (default value). At level 1, output is GC duration. At level 2, output is duration of GC phases. At level 3, output is duration of each GC steps + tasks execution (TASKS output).
When verbose level is set, GC output is (all ticks are microseconds) :
- Level 1 : GC_EVENT X:n : New event GC of type X raised by the scheduler at system tick n. X is R for restrict GC and G for global GC.
- Level 2 : GB:w(n) : GC begins for worker w at tick n
- Level 2 : SB:w(n) : Snapshot begins for worker w
- Level 2 : SW:w(n) : Worker w has ended its snapshot
- Level 2 : SE:w(n) : Snapshot step is finished (by worker w).
- Level 2 : MB:w(n) : Mark phase begins for worker w
- Level 3 : MS:w(n) : Mark step begins for worker w
- Level 3 : MT:w(n) : Mark step ends for worker w
- Level 2 : ME:w(n) : Mark phase ends for worker w
- Level 2 : WB:w(n) : Sweep phase begins (by worker w)
- Level 3 : WS:w(n) : Sweep step begins for worker w
- Level 3 : WO:w(n) : Sweep step (object sweep) ends for worker w
- Level 3 : WR:w(n) : Sweep step (raw memory sweep) ends for worker w
- Level 2 : GE:w(n) : GC ends for worker w
- Level 1 : GF:w(n) : GC ends for all worker (last worker is w)
VII - Some tests...
We are going to run some tests to see how this incremental GC works and, to do so, we must look how tasks run at microsecond level. Many things that were negligeable have now a big impact and will have impact on GC output :
- OS scheduler : OS scheduler decides which threads will run. It can decide to run or not run a worker and this can have a very big influence. For instance, on Windows, the OS scheduler tick is about 16000 microseconds. So a worker can be seen as not running its GC phase during 16000 (or more). On Linux systems, OS scheduler tick is about 1000 microseconds so the impact is not so important (but not negligeable at all). There is not much to do about it : this is the way those OS work.
- Console : at microsecond level, output on console is not negligeable at all. On windows for instance, it can be 400/500 microseconds. To see something, you should always redirect GC output to a file and not display it on a console.
- Getting time : Even getting a tick from the system, calculate a duration and sending it to a file is no more a negligeable task (after all 1 microsecond is "just" 1000 nanoseconds). So you will notice ticks increasing by 1 just because GC itself is running in verbose mode.
So, let's begin : those tests have been launched on a Core I7 laptop running on Windows 8.1 with oforth V0.9.22 x86 32bits release.
First, we can just launch oforth interpreter using GC verbose mode at level 3 :
oforth --i --XV3
And... nothing happens : GC won't run unless a minimum memory is allocated and default is 1024 Ko. We have to set this paramater to a smaller value (1Ko for instance)
oforth --i --XM1 --XV3
Now we see GC output. Each 120 ms a new line is printed with GC output :
GC_EVENT R:483135451742; TASK; GB:1(615); SB:1(936); SW:1(1149); SE:1(1359); MB:1(1531); TASK; MS:1(1685); ME:1(1835); TASK; WB:1(2048); WS:1(2213); WO:1(2318); TASK; WS:1(2438); WR:1(2559); TASK; WS:1(2693); GE:1(2831); GF:1(3030); TASK NOGC
Each (number) is the number of microseconds elapsed since GC event has been raised by the scheduler. But, we see huges numbers here (3 milliseconds for the full GC phase). This is because... we output on console. We must redirect output to a file to see something more accurate.
oforth --i --XM1 --XV3 > gc.txt
Now, if we open the file, we can see lines like :
GC_EVENT R:483460306294; TASK; GB:1(149); SB:1(152); SW:1(164); SE:1(164); MB:1(165); TASK; MS:1(167); ME:1(167); TASK; WB:1(168); WS:(171); WO:1(173); TASK; WS:1(176); WR:1(178); TASK; WS:1(181); GE:1(182); GF:1(182); TASK NOGC
We see that :
- Only one worker is running the GC : at startup, one worker is instanciated.
- This line represents a Restrict GC phase (R after GC_EVENT).
- The worker 1 detects the GC event and begins GC 149 microseconds after the event. Before this, the worker runs tasks (if any).
- Snapshot duration is 15 microseconds (SE:164 - GB:149)
- Mark phase duration is 2 microseconds (ME:167 - MB:165) : one mark step was launched.
- Sweep phase duration is 14 microseconds (GE:182 - WB:168) : 3 sweep steps were launched.
- Between GC steps, CPU is given back to tasks (TASK), but, here, the interpreter is waiting so, CPU is given back to GC almost immediately.
- Total GC duration phase (including GC output and switchs between GC and task) is 33 microseconds (GF:182 - GB:149).
So when an oforth system has started and is idle, GC cost is about 50 microseconds every 120 milliseconds (well, if --XM1 option is set...).
Second test : plenty of small object instanciations.
Let's create lots of objects and see how the GC reacts. We put this f word into a file (a file gc.of is already included into examples directory with all those words already defined)
: f(n)
| i | n loop: i [ Object new drop ] ;
Then, we run (and bench it) while we create 100000000 objects (and we do this 10 times). The --O option removes runtime tests for data stack underflow or overflow, but there is not much differences :
oforth --i --O --XV3 --P"#[ #[ 100000000 f ] bench ] times(10)" examples/gc.of > gc.txt
Lines included into gc.txt file are now much more longer :
GC_EVENT R:485902412865; TASK; GB:1(7); SB:1(9); SW:1(10); SE:1(11); MB:1(11); TASK; MS:1(17); ME:1(18); TASK; WB:1(18); WS:1(24); WO:1(246); TASK; WS:1(252); WO:1(312); TASK; WS:1(318); WO:1(378); TASK; WS:1(383); WO:1(443); TASK; WS:1(449); WO:1(508); TASK; WS:1(513); WO:1(573); TASK; WS:1(578); WO:1(637); TASK; WS:1(643); WO:1(702); TASK; WS:1(708); WO:1(767); TASK; WS:1(773); WO:1(832); TASK; WS:1(838); WO:1(897); TASK; WS:1(903); WO:1(962); TASK; WS:1(968); WO:1(1028); TASK; WS:1(1034); WO:1(1092); TASK; WS:1(1098); WO:1(1158); TASK; WS:1(1164); WO:1(1224); TASK; WS:1(1229); WO:1(1289); TASK; WS:1(1295); WO:1(1354); TASK; WS:1(1359); WO:1(1419); TASK; WS:1(1424); WO:1(1483); TASK; WS:1(1489); WO:1(1548); TASK; WS:1(1554); WO:1(1614); TASK; WS:1(1619); WO:1(1679); TASK; WS:1(1684); WO:1(1743); TASK; WS:1(1749); WO:1(1809); TASK; WS:1(1814); WO:1(1874); TASK; WS:1(1880); WO:1(1938); TASK; WS:1(1944); WO:1(2005); TASK; WS:1(2011); WO:1(2070); TASK; WS:1(2075); WO:1(2136); TASK; WS:1(2142); WO:1(2201); TASK; WS:1(2206); WO:1(2266); TASK; WS:1(2272); WO:1(2330); TASK; WS:1(2336); WO:1(2396); TASK; WS:1(2401); WO:1(2460); TASK; WS:1(2466); WO:1(2526); TASK; WS:1(2533); WO:1(2593); TASK; WS:1(2598); WO:1(2659); TASK; WS:1(2665); WO:1(2726); TASK; WS:1(2731); WO:1(2791); TASK; WS:1(2797); WO:1(2857); TASK; WS:1(2863); WO:1(2922); TASK; WS:1(2928); WO:1(2988); TASK; WS:1(2995); WO:1(3056); TASK; WS:1(3062); WO:1(3180); TASK; WS:1(3187); WO:1(3254); TASK; WS:1(3261); WO:1(3323); TASK; WS:1(3329); WO:1(3388); TASK; WS:1(3394); WO:1(3453); TASK; WS:1(3459); WO:1(3518); TASK; WS:1(3524); WO:1(3583); TASK; WS:1(3589); WO:1(3648); TASK; WS:1(3654); WO:1(3713); TASK; WS:1(3719); WO:1(3778); TASK; WS:1(3784); WO:1(3843); TASK; WS:1(3849); WO:1(3908); TASK; WS:1(3914); WO:1(3974); TASK; WS:1(3980); WO:1(4042); TASK; WS:1(4053); WO:1(4120); TASK; WS:1(4127); WO:1(4201); TASK; WS:1(4208); WO:1(4270); TASK; WS:1(4277); WO:1(4339); TASK; WS:1(4345); WO:1(4406); TASK; WS:1(4412); WO:1(4471); TASK; WS:1(4477); WO:1(4536); TASK; WS:1(4541); WO:1(4611); TASK; WS:1(4617); WO:1(4676); TASK; WS:1(4682); WO:1(4741); TASK; WS:1(4747); WO:1(4806); TASK; WS:1(4812); WO:1(4871); TASK; WS:1(4877); WO:1(4935); TASK; WS:1(4941); WO:1(5001); TASK; WS:1(5007); WO:1(5066); TASK; WS:1(5072); WO:1(5131); TASK; WS:1(5137); WO:1(5197); TASK; WS:1(5203); WO:1(5262); TASK; WS:1(5268); WO:1(5327); TASK; WS:1(5333); WO:1(5392); TASK; WS:1(5398); WO:1(5457); TASK; WS:1(5463); WO:1(5522); TASK; WS:1(5528); WO:1(5587); TASK; WS:1(5593); WO:1(5651); TASK; WS:1(5657); WO:1(5716); TASK; WS:1(5722); WO:1(5781); TASK; WS:1(5787); WO:1(5846); TASK; WS:1(5852); WO:1(5911); TASK; WS:1(5917); WO:1(5976); TASK; WS:1(5982); WO:1(6045); TASK; WS:1(6051); WO:1(6111); TASK; WS:1(6116); WO:1(6175); TASK; WS:1(6182); WO:1(6241); TASK; WS:1(6247); WO:1(6306); TASK; WS:1(6312); WO:1(6371); TASK; WS:1(6376); WO:1(6436); TASK; WS:1(6442); WO:1(6501); TASK; WS:1(6507); WO:1(6565); TASK; WS:1(6571); WO:1(6630); TASK; WS:1(6636); WO:1(6696); TASK; WS:1(6702); WO:1(6760); TASK; WS:1(6766); WO:1(6825); TASK; WS:1(6831); WO:1(6890); TASK; WS:1(6896); WO:1(6955); TASK; WS:1(6961); WO:1(7021); TASK; WS:1(7026); WO:1(7086); TASK; WS:1(7091); WO:1(7151); TASK; WS:1(7156); WO:1(7217); TASK; WS:1(7222); WO:1(7281); TASK; WS:1(7287); WO:1(7346); TASK; WS:1(7352); WO:1(7411); TASK; WS:1(7417); WO:1(7476); TASK; WS:1(7482); WO:1(7542); TASK; WS:1(7548); WO:1(7607); TASK; WS:1(7613); WO:1(7672); TASK; WS:1(7678); WO:1(7737); TASK; WS:1(7743); WO:1(7802); TASK; WS:1(7808); WO:1(7876); TASK; WS:1(7883); WO:1(7956); TASK; WS:1(7967); WO:1(8075); TASK; WS:1(8081); WO:1(8174); TASK; WS:1(8185); WO:1(8268); TASK; WS:1(8273); WO:1(8358); TASK; WS:1(8367); WO:1(8471); TASK; WS:1(8478); WO:1(8536); TASK; WS:1(8542); WO:1(8602); TASK; WS:1(8608); WO:1(8675); TASK; WS:1(8680); WO:1(8738); TASK; WS:1(8744); WO:1(8817); TASK; WS:1(8823); WO:1(8882); TASK; WS:1(8897); WO:1(8954); TASK; WS:1(8960); WO:1(9029); TASK; WS:1(9034); WO:1(9093); TASK; WS:1(9099); WO:1(9159); TASK; WS:1(9165); WO:1(9224); TASK; WS:1(9230); WO:1(9289); TASK; WS:1(9295); WO:1(9354); TASK; WS:1(9360); WO:1(9421); TASK; WS:1(9427); WO:1(9486); TASK; WS:1(9492); WO:1(9551); TASK; WS:1(9557); WO:1(9616); TASK; WS:1(9622); WO:1(9681); TASK; WS:1(9687); WO:1(9746); TASK; WS:1(9752); WO:1(9811); TASK; WS:1(9817); WO:1(9876); TASK; WS:1(9882); WO:1(9941); TASK; WS:1(9947); WO:1(10007); TASK; WS:1(10016); WO:1(10076); TASK; WS:1(10083); WO:1(10144); TASK; WS:1(10151); WO:1(10210); TASK; WS:1(10216); WO:1(10275); TASK; WS:1(10281); WO:1(10340); TASK; WS:1(10346); WO:1(10406); TASK; WS:1(10412); WO:1(10471); TASK; WS:1(10477); WO:1(10536); TASK; WS:1(10542); WO:1(10601); TASK; WS:1(10606); WO:1(10666); TASK; WS:1(10672); WO:1(10732); TASK; WS:1(10739); WO:1(10799); TASK; WS:1(10805); WO:1(10871); TASK; WS:1(10877); WO:1(10936); TASK; WS:1(10942); WO:1(11001); TASK; WS:1(11008); WO:1(11071); TASK; WS:1(11078); WO:1(11138); TASK; WS:1(11144); WO:1(11203); TASK; WS:1(11209); WO:1(11268); TASK; WS:1(11274); WO:1(11333); TASK; WS:1(11339); WO:1(11398); TASK; WS:1(11404); WO:1(11463); TASK; WS:1(11469); WO:1(11527); TASK; WS:1(11533); WO:1(11593); TASK; WS:1(11598); WO:1(11658); TASK; WS:1(11664); WO:1(11723); TASK; WS:1(11728); WO:1(11788); TASK; WS:1(11793); WO:1(11853); TASK; WS:1(11859); WO:1(11918); TASK; WS:1(11924); WO:1(11990); TASK; WS:1(11999); WO:1(12060); TASK; WS:1(12066); WO:1(12126); TASK; WS:1(12132); WO:1(12191); TASK; WS:1(12197); WO:1(12281); TASK; WS:1(12287); WO:1(12347); TASK; WS:1(12352); WO:1(12411); TASK; WS:1(12418); WO:1(12476); TASK; WS:1(12482); WO:1(12541); TASK; WS:1(12547); WO:1(12606); TASK; WS:1(12612); WO:1(12671); TASK; WS:1(12677); WO:1(12736); TASK; WS:1(12742); WO:1(12801); TASK; WS:1(12806); WO:1(12869); TASK; WS:1(12875); WO:1(12940); TASK; WS:1(12946); WO:1(13006); TASK; WS:1(13012); WO:1(13093); TASK; WS:1(13103); WO:1(13168); TASK; WS:1(13174); WO:1(13240); TASK; WS:1(13246); WO:1(13315); TASK; WS:1(13321); WO:1(13419); TASK; WS:1(13428); WO:1(13538); TASK; WS:1(13547); WO:1(13630); TASK; WS:1(13638); WO:1(13698); TASK; WS:1(13706); WO:1(13774); TASK; WS:1(13779); WO:1(13854); TASK; WS:1(13863); WO:1(13929); TASK; WS:1(13935); WO:1(14012); TASK; WS:1(14018); WO:1(14078); TASK; WS:1(14083); WO:1(14149); TASK; WS:1(14155); WO:1(14226); TASK; WS:1(14236); WO:1(14312); TASK; WS:1(14318); WO:1(14377); TASK; WS:1(14383); WO:1(14445); TASK; WS:1(14451); WO:1(14510); TASK; WS:1(14516); WO:1(14554); TASK; WS:1(14560); WO:1(14575); TASK; WS:1(14581); WR:1(14583); TASK; WS:1(14589); GE:1(14589); GF:1(14590); TASK NOGC
We can see that :
- The worker detects the GC event quicker (7 microseconds) : this is because the interpreter task is now running and not waiting for console events.
- The snapshot step is very fast (4 microseconds) : there is only one task and it keeps almost no objects on data stack or return stack.
- The mark phase is very fast too (7 microseconds) : same reason.
- For this reason, there are no differences between Restrict GC lines and Global GC lines : differences are important during the mark phase.
- The sweep phase is long : 14500 microseconds ie 14 milliseconds : lots of unused objects have to be released during the sweep phase.
- Each sweep step last about 60 microseconds : tests are done on a core i7, GC default parameters are tuned for a 80/100 microseconds by step on a Core i5.
- Task between each GC sweep step run very quickly : 6 or 7 microseconds between GC steps. This is because, in this case, the task consumes its ticks very quickly (each object creation consumes one tick). Here, it could be interesting to increase the --XA parameter (300 ticks by default).
- Oforth creates and free those 100 millions objects in about 1,3 seconds ie about 13 nanoseconds by object.
Let's say 1 millisecond GC steps duration is enough for you application and you would like to have the task running more between those steps, you can run oforth using those parameters (6000 x 10 for gc steps and 300 x 10 for tasks :
oforth --i --O --XG60000 --XA3000 --XV3 --P"#[ #[ 100000000 f ] bench ] times(10)" examples/gc.of > gc.txt
Now lines into the file are shorter :
GC_EVENT R:490552034659; TASK; GB:1(6); SB:1(8); SW:1(9); SE:1(9); MB:1(10); TASK; MS:1(226); ME:1(227); TASK; WB:1(227); WS:1(280); WO:1(833); TASK; WS:1(887); WO:1(1462); TASK; WS:1(1516); WO:1(2092); TASK; WS:1(2146); WO:1(2697); TASK; WS:1(2751); WO:1(3327); TASK; WS:1(3381); WO:1(3932); TASK; WS:1(3997); WO:1(4580); TASK; WS:1(4633); WO:1(5186); TASK; WS:1(5240); WO:1(5792); TASK; WS:1(5845); WO:1(6420); TASK; WS:1(6474); WO:1(7073); TASK; WS:1(7127); WO:1(7680); TASK; WS:1(7734); WO:1(8328); TASK; WS:1(8382); WO:1(8935); TASK; WS:1(8989); WO:1(9543); TASK; WS:1(9597); WO:1(10173); TASK; WS:1(10227); WO:1(10779); TASK; WS:1(10840); WO:1(11399); TASK; WS:1(11450); WO:1(12015); TASK; WS:1(12089); WO:1(12647); TASK; WS:1(12699); WO:1(13280); TASK; WS:1(13332); WO:1(13820); TASK; WS:1(13871); WR:1(13873); TASK; WS:1(13924); GE:1(13924); GF:1(13925); TASK NOGC
- GC sweep steps now last about 600/800 microseconds.
- Task are running during about 50/60 microseconds between those steps.
Next example : long lived objects
This example will show how the GC behaves during the mark phase. A good benchmark to test memory allocation is the binarytree test. You can find explainations here :
http://benchmarksgame.alioth.debian.org/u32/performance.php?test=binarytrees
Oforth version of binarytree test is included into the example folder (binarytree.of). It is a version that will use all available workers (default is number of cores).
Object Class new: TreeNode(item, l, r)
TreeNode method: initialize // rnode lnode item --
:= item := l := r ;
TreeNode method: check -- n
@item @l ifNotNull: [ @l check + @r check - ] ;
: bottomUp(item, depth) -- aTreeNode
depth ifZero: [ null null ]
else: [ depth 1 - item dup + over over bottomUp tor 1 - bottomUp ]
item TreeNode new ;
: printTree(n, depth, v)
System.Out n << depth << "\t check: " << v << cr ;
: gentrees(dep, it) -- aBlock
| res i |
0 it loop: i [ bottomUp(i, dep) check + bottomUp(0 i -, dep) check + ] ->res
#[ printTree(it 2 * "\t trees of depth " + , dep, res) ] ;
: binarytree(N)
| depth minDepth maxDepth stretch longLived |
4 dup ->minDepth 2 + N max dup ->maxDepth 1 + ->stretch
printTree("stretch tree of depth ", stretch, bottomUp(0, stretch) check)
bottomUp(0, maxDepth) ->longLived
ListBuffer new
minDepth maxDepth 2 step: depth
[ #[ gentrees(depth, 1 bitLeft(maxDepth depth - minDepth +)) ] over add ]
mapParallel(#perform) apply(#perform)
printTree("long lived tree of depth ", maxDepth, longLived check) ;
This test is a good test because it allocates a huge long-lived binary tree (depth 20) which will live-on while other trees are allocated and desallocated. Let's run this test with only 1 worker ( --W command line option) :
oforth --O --XV3 --P"#[ binarytree(20) ] bench" --W1 examples/binarytree.of > gc.txt
This test runs in about 20 seconds on one core (100% usage of the core). When we check the file gc.txt, we see that :
- Snapshot is still very fast (about 10 microseconds) : the long lived tree counts only for 1 object during the snapshot.
- There is a huge difference between a restrict GC and a global GC : the long lived tree is an immutable object that is only checked during global GC.
- The mark phase is fast during restrict GC but very long during global GC (sometimes about 40000 microseconds ie 40 milliseconds).
- The sweep phase is stable : about 8000/9000 microseconds and each GC steps is about 60 microseconds.
- Tasks are running 10/12 microseconds between GC steps.
We can run this test with 4 workers (using --W4 if you have more than 4 cores or without parameters if you have 4 cores on your machine) :
oforth --O --XV3 --P"#[ binarytree(20) ] bench" --W4 examples/binarytree.of > gc.txt
This test runs in about 8,5 seconds. On each line, you can see that, now, the 4 workers are participating to the GC phase. Not all of these are working during the mark phase (it depends if a worker is retrieving a task or not during the snapshot).
It is common to hear that, with a mark and sweep GC, the critical part is the sweep phase (check of all the heap to release objects, ...). Well, with this GC, it is not the case :
- The sweep phase is the simpliest one.
- Even under high object allocation rate, and multiple workers it will not last more that 15000 microseconds (each worker handle its heap).
- Sweep steps duration are guaranted to be less than 100 microseconds (or the --XG parameter).
Here, the critical part is the mark phase :
- Global mark duration can be very long (40 milliseconds) if lots of long-lived objects have to be marked.
- At least with this version, there are restrictions on mark steps duration to last less than 100 microseconds (see chapter 5).
- With this version, workers that have finished their mark stack don't helps others : they run tasks until the mark phase is finished. It would be great, in the last example, if the 3 workers helped the poor one that retrieved the task that hold the long lived tree during a global GC... This could be a great improvement (perhap's in a futur version) to limit mark stack duration.
- During the mark phase, objects creations are conservatives : they are marked as USED even for short lived objects. So, if the mark phase is long, memory used will be larger.
Compared to this, the sweep phase is a so much simplier...
To be continued...
Franck